kNN을 이용한 숫자 인식¶
Goal¶
- kNN Machine Learning 알고리즘을 이용하여 손글씨 숫자를 인식할 수 있다.
이번에는 kNN방식을 이용하여 손글씨 숫자를 인식하는 예제를 진행하도록 하겠습니다. 우선 traning data가 필요합니다. 아래는 Open CV에서 제공하는 Sample용 손글씨 이미지 입니다.

가로 100개, 세로 50개로 총 5000개의 숫자가 있습니다. 각 숫자는 20x20의 해상도를 가지고 있습니다. kNN을 이용하기 위해서 학습하기와 테스트로 나눠서 진행하겠습니다.
학습하기¶
- 우선 위 이미지를 가로/세로롤 잘라서 하나의 숫자를 배열에 넣습니다.
- 그러면 순서대로 0부터 9까지 각각 500개씩 배열에 넣어집니다.
- 배열값이 0 ~ 499까지는 1, 500 ~ 999까지는 2 ... 4499 ~ 4999는 9를 의미하는 이미지 값이 들어가게 됩니다.
- 그러면 500개씩 Loop를 수행하면서 각 배열에 Label작업을 합니다.
- 그리고 이 결과값으 numpy파일로 저장을 합니다.
테스트¶
- 학습한 numpy파일을 Load합니다.
- 마우스나 사진으로 찍은 손글씨 숫자를 학습할 때 사용한 동일한 해상도(20X20)으로 Resize를 합니다.
- kNN 알고리즘을 통해서 손글씩 숫자를 인식합니다.
재학습¶
- 테스트시 실제 손글씨와 컴퓨터가 인식한 값이 다를 경우 사람이 정확한 값을 입력해 줍니다.
- 이 값은 다시 numpy파일에 추가가 되어 재학습이 이루어 집니다.
아래는 학습과 테스트를 수행하는 예제입니다.
#-*- coding: utf-8 -*-
import cv2
import numpy as np
import glob
import sys
FNAME = 'digits.npz'
def machineLearning():
img = cv2.imread('images/digits.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
x = np.array(cells)
train = x[:,:].reshape(-1,400).astype(np.float32)
k = np.arange(10)
train_labels = np.repeat(k,500)[:,np.newaxis]
np.savez(FNAME,train=train,train_labels = train_labels)
def resize20(pimg):
img = cv2.imread(pimg)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
grayResize = cv2.resize(gray,(20,20))
ret, thresh = cv2.threshold(grayResize, 125, 255,cv2.THRESH_BINARY_INV)
cv2.imshow('num',thresh)
return thresh.reshape(-1,400).astype(np.float32)
def loadTrainData(fname):
with np.load(fname) as data:
train = data['train']
train_labels = data['train_labels']
return train, train_labels
def checkDigit(test, train, train_labels):
knn = cv2.ml.KNearest_create()
knn.train(train, cv2.ml.ROW_SAMPLE, train_labels)
ret, result, neighbours, dist = knn.findNearest(test, k=5)
return result
if __name__ == '__main__':
if len(sys.argv) == 1:
print 'option : train or test'
exit(1)
elif sys.argv[1] == 'train':
machineLearning()
elif sys.argv[1] == 'test':
train, train_labels = loadTrainData(FNAME)
saveNpz = False
for fname in glob.glob('images/num*.png'):
test = resize20(fname)
result = checkDigit(test, train, train_labels)
print result
k = cv2.waitKey(0)
if k > 47 and k<58:
saveNpz = True
train = np.append(train, test, axis=0)
newLabel = np.array(int(chr(k))).reshape(-1,1)
train_labels = np.append(train_labels, newLabel,axis=0)
cv2.destroyAllWindows()
if saveNpz:
np.savez(FNAME,train=train, train_labels=train_labels)
else:
print 'unknow option'
함수단위로 간단히 설명을 하면
- machineLearing
- resize20
- loadTrainData
- checkDigit
먼저 학습을 수행합니다. 학습을 수행하기 위해서 아래와 같이 입력합니다.
>>> python matchDigits.py train
위 작업을 수행하면 해당 폴더에 digits.npz 파일이 생성이 되어 있습니다. 이 파일이 학습한 결과 입니다.
이제 테스트를 진행해보겠습니다.
>>> python matchDigits.py test
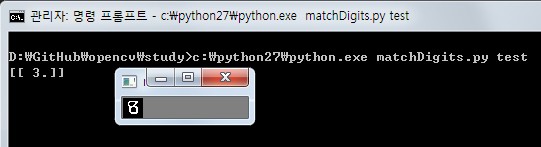
위 화면에서 commnad창에 있는 숫자가 컴퓨터가 인식한 숫자이고, 오른쪽 작은 창에 있는 숫자가 테스트로 제공된 숫자입니다.
이렇게 잘못된 결과가 나왔을 때 정확한 값을 입력해주면 재학습이 이루어 집니다. 맞았을 경우는 숫자가 아닌 key를 눌러 다음 test로 넘어 갑니다.
아래는 첫번째 테스트의 결과 입니다.
- 첫번째 테스트 결과
| 손글씨 | 8 | 5 | 4 | 9 | 9 | 1 | 7 | 1 | 6 | 3 | 2 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 결과1 | 3 | 5 | 1 | 7 | 1 | 1 | 4 | 1 | 5 | 5 | 2 | 4 |
총 12개의 Sample에서 3번밖에 맞지 않았습니다. 이것은 학습에서 제공되었던 Data와 Test를 위해 마우스로 작성한 손글씨에 차이가 많이 있었기 때문입니다. 하지만 첫번째 테스트에서 재학습을 했기 때문에 다음 Test에서는 적중률이 더 높아 질 것 입니다.
그럼 다시 테스트를 진행하겠습니다.
| 손글씨 | 8 | 5 | 4 | 9 | 9 | 1 | 7 | 1 | 6 | 3 | 2 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 결과2 | 3 | 5 | 1 | 7 | 1 | 1 | 4 | 1 | 5 | 3 | 2 | 0 |
이번에는 12개중 5개가 맞았습니다. 한번 더 진행해 보겠습니다.
| 손글씨 | 8 | 5 | 4 | 9 | 9 | 1 | 7 | 1 | 6 | 3 | 2 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 결과3 | 6 | 5 | 1 | 7 | 1 | 1 | 4 | 1 | 6 | 3 | 2 | 0 |
| 결과4 | 8 | 5 | 1 | 9 | 9 | 1 | 7 | 1 | 6 | 3 | 2 | 0 |
| 결과5 | 8 | 5 | 4 | 9 | 9 | 1 | 7 | 1 | 6 | 3 | 2 | 0 |
총 4번의 테스트와 재학습결과 100% 적중률을 보였습니다. 이런식으로 많은 Data와 재학습을 통하면 정확도가 높아지게 됩니다.